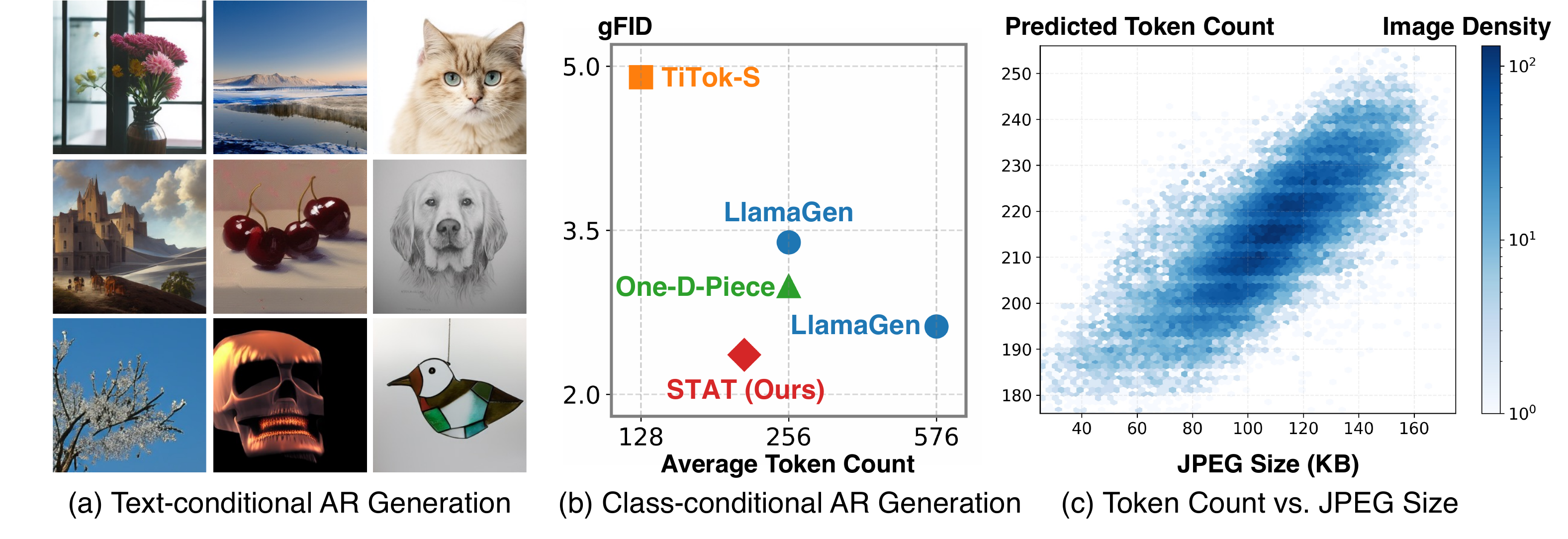
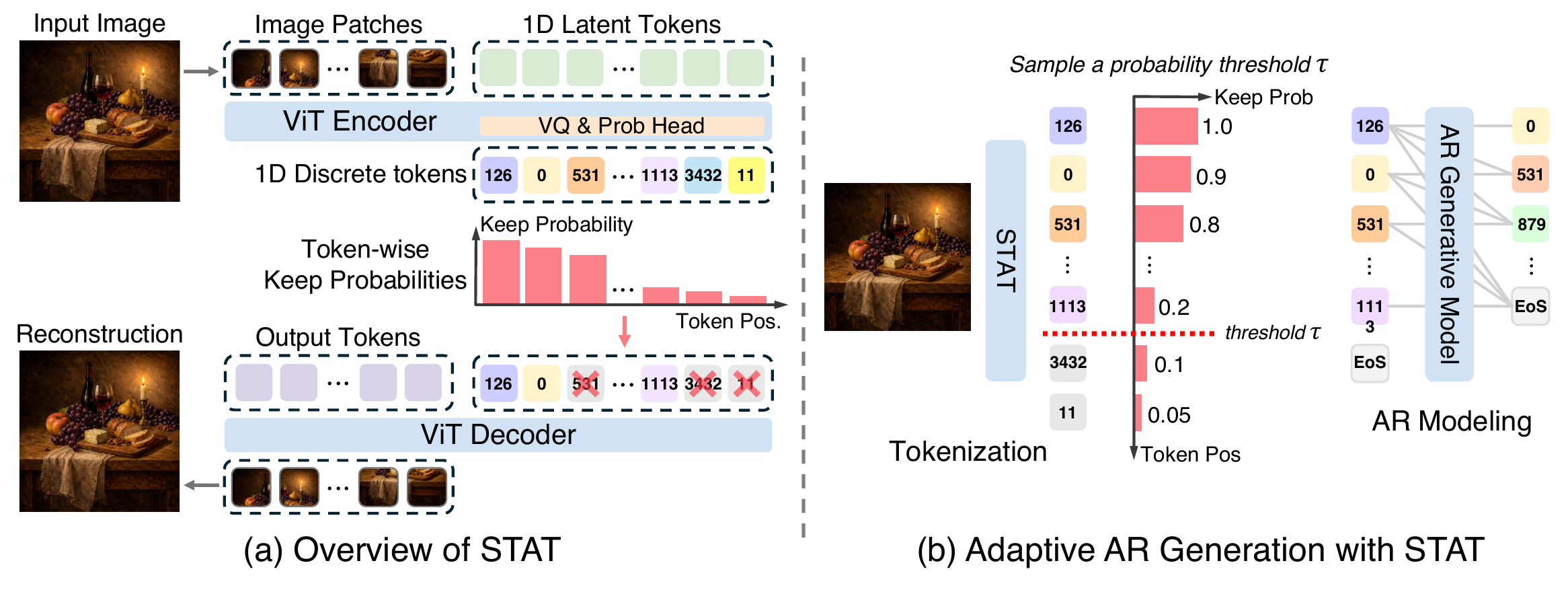
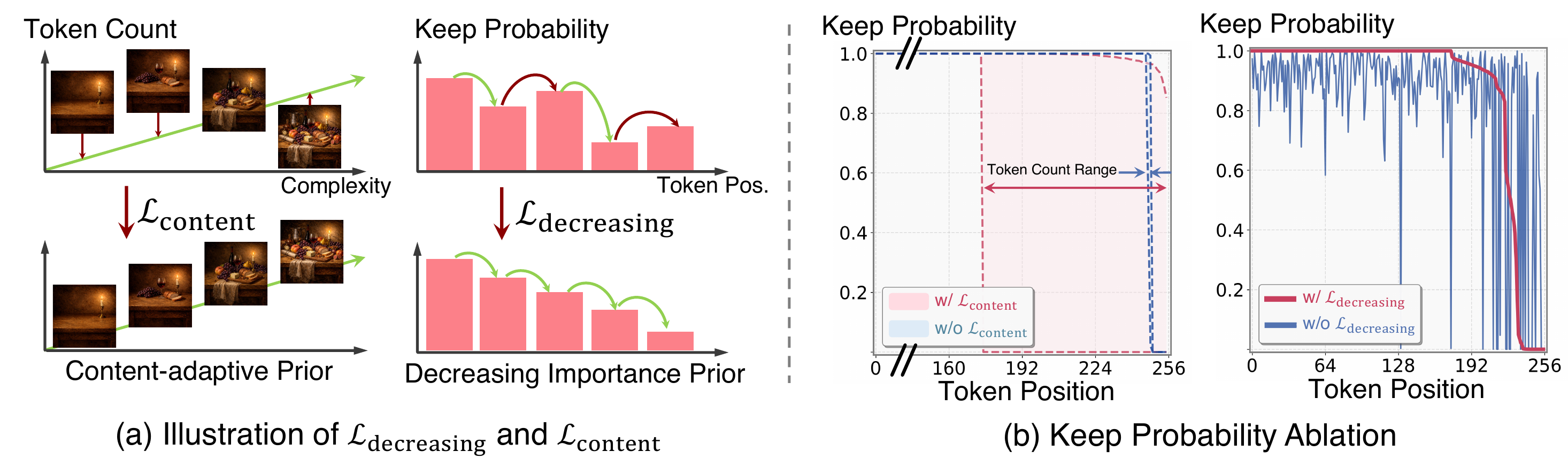
We present Soft Tail-dropping Adaptive Tokenizer (STAT), a discrete tokenizer that learns adaptive visual representations. STAT adjusts the number of tokens allocated to each image according to its perceptual complexity. Specifically, it encodes an image into discrete tokens together with token-wise keep probabilities indicating whether each token is necessary for faithful reconstruction or can be safely dropped. Through this learned adaptivity, STAT achieves state-of-the-art reconstruction quality while using fewer tokens on average. When integrated with vanilla causal autoregressive (AR) modeling, STAT enables a content-aware generative model with adaptive-length sampling. The model achieves competitive or superior visual generation quality compared with other generative model families while exhibiting favorable scaling behavior that has been elusive in prior vanilla AR visual generation attempts.
Samples generated by a vanilla autoregressive model with STAT. Click any image to enlarge and read its prompt.

A pineapple surfing on a wave

A painting of a fox in the style of starry night

A colorful coral reef bustling with marine life

A snowy mountain peak with blue sky

A steampunk airship floating above a Victorian-era city

A painting of a sport car in the style of Monet

The word “START” written on a street surface

A watercolor painting of a small European village by a river

A spaceship descending into a volcanic alien landscape

A glowing magical sword floating above an ancient altar

A medieval alchemist's laboratory filled with mysterious potions

A cozy cabin interior with a fireplace during a snowstorm

A wolf standing on a snowy ridge during golden hour

A pickup truck driving through a desert environment

A vintage red sports car parked on a coastal highway at sunset

A cup of cappuccino with latte art

A high-speed photograph of a splash forming a crown shape

A woman in a minimalistic studio portrait

An illustration of a teapot

Yin-yang
Drag the slider to decode the same image with more or fewer tokens. STAT's predicted token count (green) already matches the full-length reconstruction — simple images need fewer tokens, complex high-frequency images need more.
Integrated with a vanilla causal autoregressive model, STAT generates with adaptive-length sampling. The model emits an end-of-sequence token (green) when the content is complete, well before the full 256-token budget.
@InProceedings{chen2026soft,
author = {Chen, Zeyuan and Zhang, Kai and Tu, Zhuowen and Xiong, Yuanjun},
title = {Soft Tail-dropping for Adaptive Visual Tokenization},
booktitle = {ECCV},
year = {2026},
}