Continuous Video Representation
Video Implicit Neural Representation (VideoINR) maps any 3D space-time coordinate to an RGB value. This nature enables extending the latent interpolation space of Space-Time Video Super Resolution (STVSR) from fixed space and time scales to arbitrary frame rate and spatial resolution.
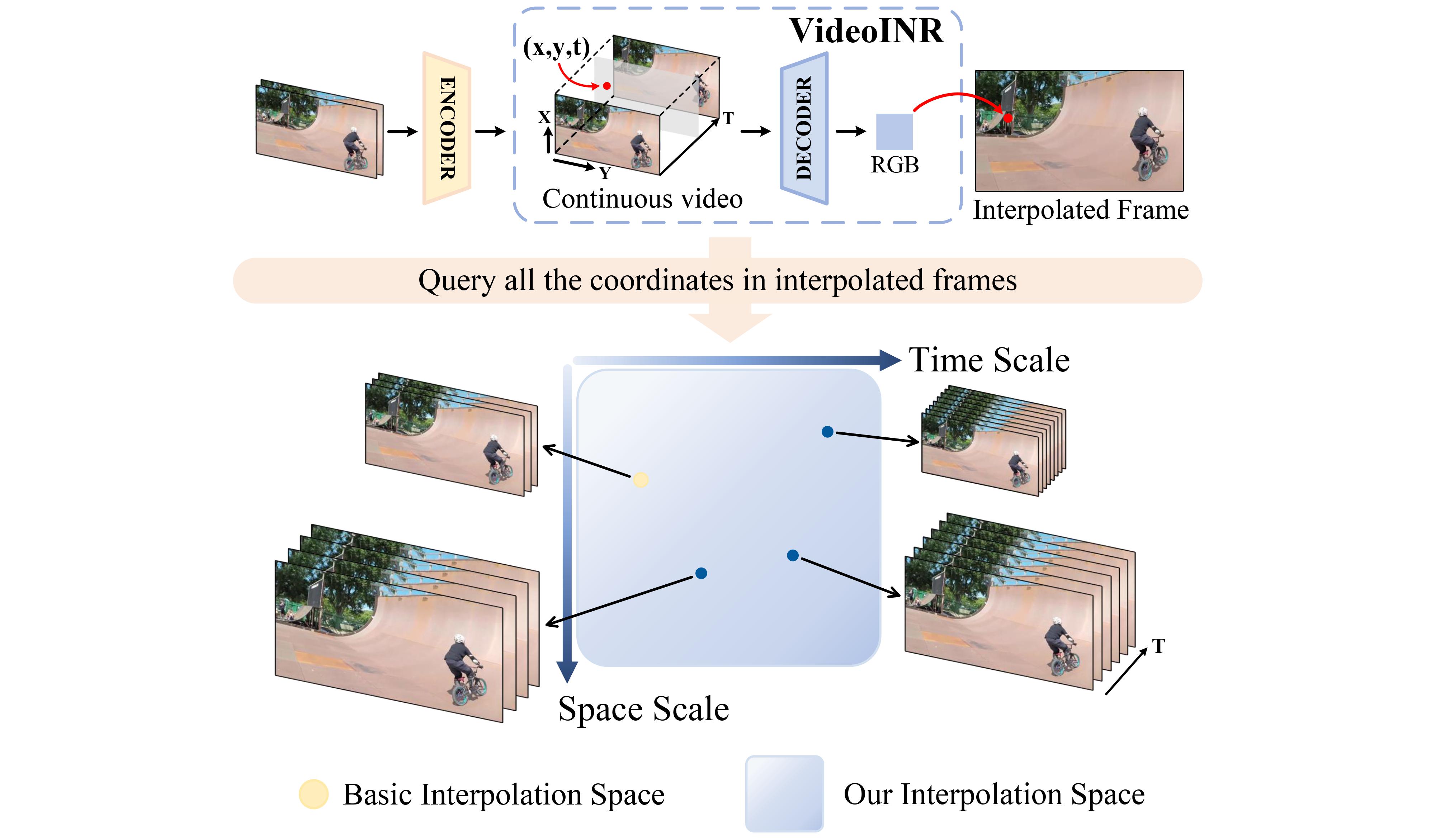
VideoINR: Pipeline
Two input frames are concatenated and encoded as a discrete feature map. Based on the feature, the spatial and temporal implicit neural representations decode a 3D space-time coordinate to a motion flow vector. We then sample a new feature vector by warping according to the motion flow, and decode it as the RGB prediction of the query coordinate. We omit the multi-scale feature aggregation part in this figure.